
致谢
- 感谢 沈同学 在学习过程中的指导
- 感谢 陆赫冉 对英文语法的校正和修改工作
OpenCV 自学源码和部分笔记
所有OpenCV-Python Tutorials内的教程
所有章节均使用Python完成实现,并且发布代码至opencv-turtorial-notes
其中几个比较核心知识点的笔记,在代码备注中存在一份,单独整理出来如下
Feature 特征点
Scale-Invariant Feature Transform
Features from Accelerated Segment Test
Binary Robust Independent Elementary Features
Oriented FAST and Rotated BRIEF
Camera 相机
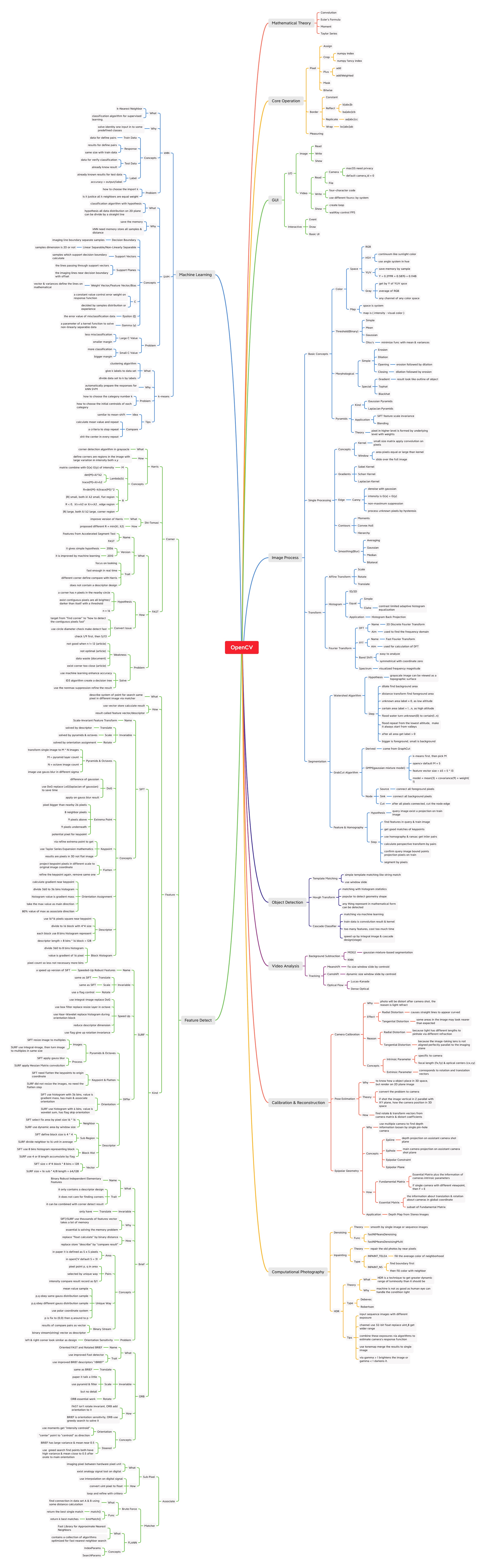
Machine Learning 机器学习
OpenCV 思维导图
後記
故事还要从2015年5月说起,那一年的夏天,我硕士生毕业了。毕业答辩上我的带有一行行错别字的作文,被老师评了80多分。
说实话这个分并不算差,能得这么高分的原因,大概也是因为毕业作文的题目和在座的诸位一样,读起来那是相当的朗朗上口,平仄有律,就一点不太好,不太容易看懂。
当初大概除了我,还有另外一个人能看懂,很可惜,这个人并不是我导师,而是万能的主。
时光荏苒,白驹过隙,五年过去之后,回过头来,应该只有主能看懂了。
每当梦境进行到这一幅画面时,我内心的想法仿佛是这个电影的画面音一样,一点点增大增大再增大,直到音量扭曲了整个胶卷和画面,只剩下卓别林式的一行话
“因为老子也不知道我论文里写的啥JB玩意啊。。。。。”
工作中每每看到这些曾经伴随我校园时光的名词术语时,总会有一丝丝的遗憾
为了不愧对于我的“通信与信息系统——工学硕士”这个张薄纸,我只好 加入了9.9学Python 走上职场巅峰 一点点啃官方教程
在啃教程的时间里,终于有一个人叩门而入,并向我喊道:
“全世界的无产阶级,联合起来 Огонь по готовности!”
在共同打守望先锋打友谊下,达瓦西里·沈教授了我过去遗失的技能。
终于,在2020年疫情还未散去的春天,樱花飘满了目黑川的东京,我终于知道我硕士毕业论文写的是什么了!